This project started as a practical follow-up to an introductory deep reinforcement learning course. The goal was simple to state and harder to make work: train deep RL agents to solve a small stochastic pickup-and-delivery task better than a hand-written greedy baseline.
The code is available on GitHub: github.com/jclotten/deep-rl-gridworld-benchmark.
Why This Project
Small gridworlds are often used to explain reinforcement learning because the rules are easy to understand. That does not mean they are automatically easy for deep RL.
In this project, we wanted to compare modern algorithms in a controlled setting:
- DQN as a value-based off-policy method
- PPO as an on-policy actor-critic method
- SAC as an off-policy actor-critic method with entropy regularization
The interesting part was not only which algorithm produced the highest final reward. It was also how much the result depended on state representation, reward shaping, exploration, and tuning.
The Environment
The task takes place in a 5x5 grid. Items appear dynamically, the agent has to collect them, and then deliver them to a target cell before the items expire. Movement has a cost, so blindly moving around the grid is punished.
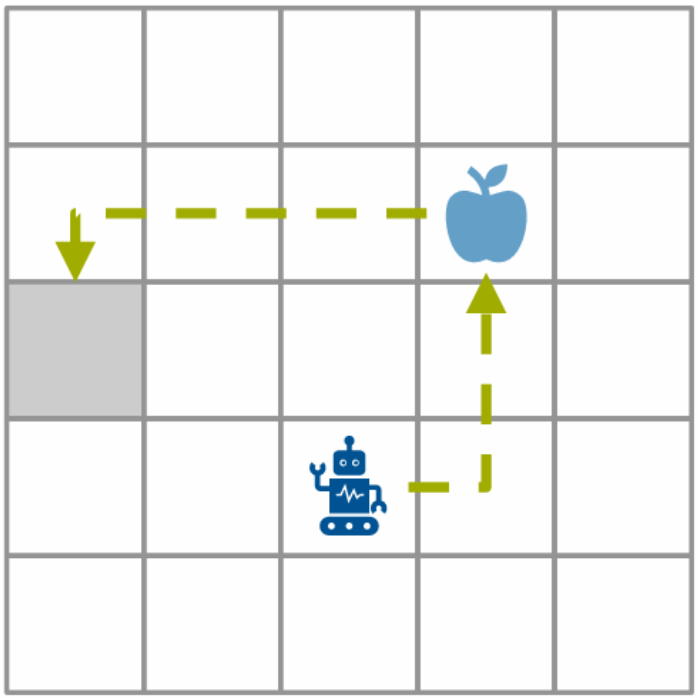
The project used three variants of the environment. The base variant is open and relatively easy to reason about. The harder variants change the reward structure, item lifetime, carrying capacity, item distribution, and spatial restrictions.
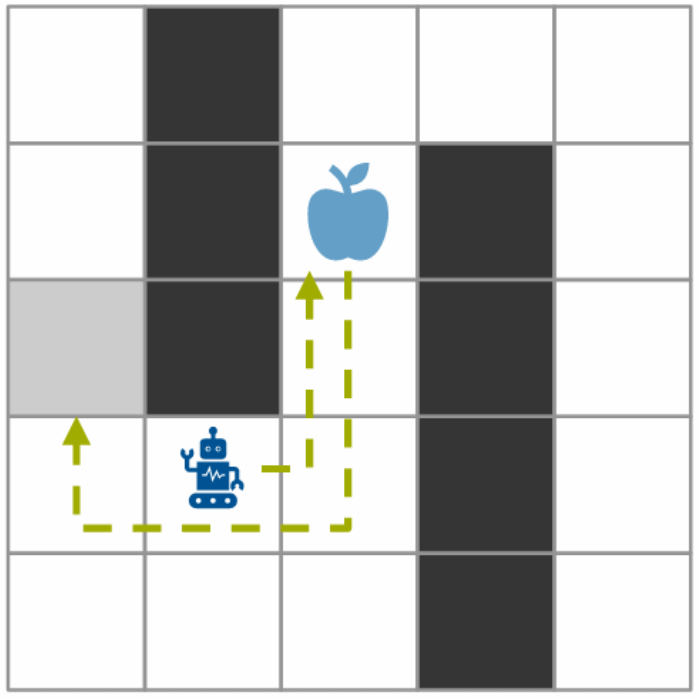
The action space was discrete: stay, move up, move right, move down, or move left. The main observation representation used an MLP-friendly feature vector with information about the agent, target, load, direction, and item state. We also tried CNN-style grid encodings early on, but those did not work well enough to keep as the main direction.
The Greedy Baseline
The baseline was a hand-written greedy policy. It computes shortest paths and moves toward reachable items if doing so looks profitable; otherwise it waits or returns to the target when carrying enough items.
That made the benchmark more interesting. The RL agents were not only trying to learn a reasonable policy from scratch, they also had to beat a compact heuristic that already encoded useful structure about the task.
In the repository, the greedy baseline reached average testing rewards around:
Variant 0: 221.770
Variant 1: 385.425
Variant 2: 250.685
Those numbers are useful context because they show why “learning something” was not enough. The learned agents had to learn something better than a sensible shortcut.
What We Tried
The project went through several phases.
First, we implemented and tested DQN with experience replay and target networks. We tried both MLP and CNN variants. The CNN approach was appealing because the environment is spatial, but in practice the simpler feature representation worked better for this project.
We then spent a lot of time on feature engineering. This mattered more than expected. Better normalized directions, item information, load state, and variant-specific hints gave the agents a much clearer learning signal.
We also tried A2C, but it was unstable in this setting and often converged to unhelpful behavior. After that, the work moved toward PPO and SAC in parallel. Both required careful tuning, but they exposed different failure modes: PPO was sensitive to seeds and exploration settings, while SAC depended heavily on reward shaping and the chosen state representation.
Experiment Setup
The experiments were tracked with Weights & Biases, and larger sweeps were run on the LRZ cluster. That was useful mostly because reinforcement learning experiments are noisy: a single run can be misleading, and small hyperparameter changes can produce very different behavior.
The sweeps covered learning rates, discount factors, entropy settings, PPO clipping, replay settings, and other algorithm-specific parameters. This was not a polished benchmark infrastructure project, but having a repeatable setup made the iteration much less chaotic.
What Ended Up Mattering
The biggest lesson was that algorithm choice was only part of the story.
Reward shaping was important. Without additional feedback, agents could spend a lot of time in low-reward behavior before discovering useful strategies. Shaping helped push them away from dead ends such as invalid moves or local loops and toward promising regions of the grid.
State representation also mattered. A small environment does not remove the need to tell the agent the right things. The agents improved once the observation vector represented the problem in a way that made item timing, direction, and delivery behavior easier to learn.
Finally, the greedy baseline was a strong reminder that deep RL is not automatically the right tool just because the problem is sequential. A simple heuristic can be hard to beat when it matches the structure of the environment.
Results
The final models outperformed the greedy baseline across the environment variants, but the path there was uneven.
DQN performed strongly on the simpler variants. SAC was the most promising on the hardest variant, where the blocked cells and changed item dynamics made exploration more difficult. PPO showed potential, but was less robust and more sensitive to tuning in the sparse-reward setting.
I would not present the takeaway as “deep RL solved the task easily.” The more accurate takeaway is that deep RL could beat the baseline after a fair amount of feature engineering, reward shaping, experiment tracking, and tuning.
What I Learned
This project made the practical side of reinforcement learning feel much more concrete.
The environment was small enough to understand, but still complex enough to show common RL problems: sparse rewards, unstable learning curves, sensitivity to seeds, and the difference between shaped training rewards and real evaluation rewards.
It also made me appreciate baselines more. The greedy policy was not sophisticated, but it gave us a clear standard to beat and helped reveal when a learned agent was only looking good because of reward shaping rather than actually solving the task.