At EPFL RoboHack 2026 in Lausanne, Switzerland, our team worked on a physical robot arm challenge: build the arm, record demonstrations, train a policy, and then see whether it could perform a precise manipulation task on the real hardware.
The short version is that we built a leader-follower setup, collected teleoperated demonstrations, and trained an imitation-learning policy to pick up a small custom object, insert it into a matching hole, and turn it into place. It was exactly the kind of robotics project where the software only makes sense once the hardware, calibration, cameras, gripper, and task design all work well enough at the same time.
The team code is available here: github.com/Encrux/robohack26.
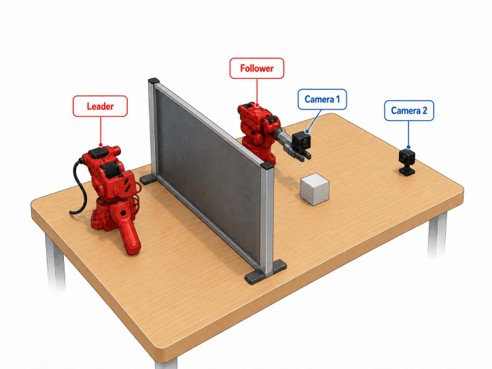
The setup in one sketch: a leader arm for demonstrations, a follower arm for the task, and camera views around the table.
A Weekend Robot Arm Project
The challenge started from parts rather than from a finished robot. We had motors, boards, and pre-printed arm components, but the robot still had to be assembled, calibrated, and made usable under hackathon time pressure.

Early setup work at the RoboHack table, before the project became mostly about data and deployment.
The setup used a leader-follower arm: one arm was moved by a human, and the second arm copied those joint positions. That gave us a practical way to collect demonstrations without writing a hand-engineered controller for the task.
This was not a clean lab setup where every detail is known in advance. It was closer to the useful kind of messy: screws, printed parts, camera streams, calibration files, motor ports, and a lot of small physical tolerances that mattered more than expected.
The Task
The manipulation task was a precise insertion problem. We used a custom printed gripper and a small key-like object. To pick it up, one long fingertip of the gripper had to go into a small hole in the object with only a few millimeters of margin. After pickup, the arm had to move the object into a matching printed keyhole and turn it into place.
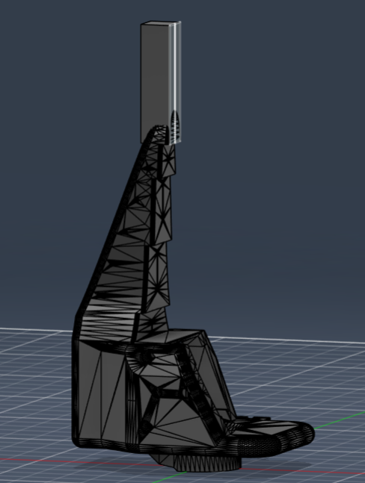
The custom gripper design, with the long fingertip that had to find the small opening in the object.
That made the task more interesting than just moving a cube from one place to another. Small alignment errors showed up immediately: the object would not be picked up, the insertion would miss, or the final turn would fail.

The printed slot made the task unforgiving in a useful way: close was still a miss.
Collecting Demonstrations
We recorded demonstrations through teleoperation. The leader arm generated the actions, the follower arm executed them, and the recording pipeline saved the observations and actions as a dataset for imitation learning.
The repo contains the supporting code around this workflow: leader-follower teleoperation, dataset recording, camera handling, training scripts, and policy deployment.
One practical detail was camera setup. We first recorded from a single external camera looking at the whole scene from above and at an angle. Later, we moved toward a more useful setup with a camera mounted near the gripper and a second camera streamed from another laptop. The robot code ran through WSL, while the cameras were streamed over HTTP/MJPEG, so the project needed a small wrapper around LeRobot’s camera handling.
We trained with two dataset sizes: roughly 50 demonstration episodes and roughly 110 demonstration episodes. The surprising part was that the smaller dataset performed better in the actual deployment.
Training the Policy
For the learned policy, the project used the LeRobot stack and trained an ACT-style imitation-learning policy from recorded demonstrations. The workflow was roughly:
teleoperate the follower arm
record demonstration episodes
train an imitation-learning policy
run the trained checkpoint on the real follower arm
The policy was not learning from reward like in reinforcement learning. It was trying to reproduce the behavior seen in the demonstrations. That made the quality and consistency of the demonstrations especially important.
Deployment
The most useful test was not whether the training loss looked good. It was whether the real arm could run the learned policy and complete the task.
One deployment attempt: pickup, move to the slot, and try the final turn.
With the better model, we saw roughly 30-40% success on picking up the key-like object and about 26% success on the full insertion-and-turning task. For a short hackathon with a freshly assembled robot and a precise physical task, that felt like a real result, but not a polished or solved system.
One behavior that stood out was that the policy sometimes seemed to retry after a failed pickup. We had not explicitly trained a separate retry behavior, and the retries were not usually successful, but it was still interesting to see the model produce something that looked like a second attempt when the first contact did not work.
The model trained on around 110 demonstrations performed worse in practice than the one trained on around 50. I would be careful not to overinterpret that. It could have been data quality, hyperparameters, training time, distribution shift, or simply the fact that there was not much time to run controlled experiments.
What Surprised Me
The biggest surprise was how quickly physical details dominated the project.
In simulation or offline ML projects, it is easy to focus mostly on the model. Here, the model was only one part of the chain. A small issue in the gripper, camera setup, calibration, object geometry, or demonstration quality could show up as a failed policy.
The second surprise was that more data was not automatically better. The 110-demonstration run sounding better on paper did not translate into better deployment performance. In imitation learning, bad or inconsistent demonstrations can be expensive.
The retry-like behavior was also memorable. It was not reliable enough to call it a solved recovery strategy, but it made the policy feel less like a simple replay of one fixed motion and more like it had picked up some structure from the demonstrations.
What I Learned
This project made robotics feel very concrete. The task was small, but the system was real: hardware had to move, cameras had to work, demonstrations had to be collected, and the learned policy had to survive contact with a physical setup.
It also made the gap between “the code runs” and “the robot does the task” very visible. Getting to an imperfect but working deployment was the interesting part.